This formulation is nice because we can interpret the \(\beta\) coefficients as the change in the log-odds of the outcome for a one unit increase in the corresponding feature.
However other choices are available e.g. using a probit model where we use the cumulative distribution function of the standard normal distribution instead of the logistic function.
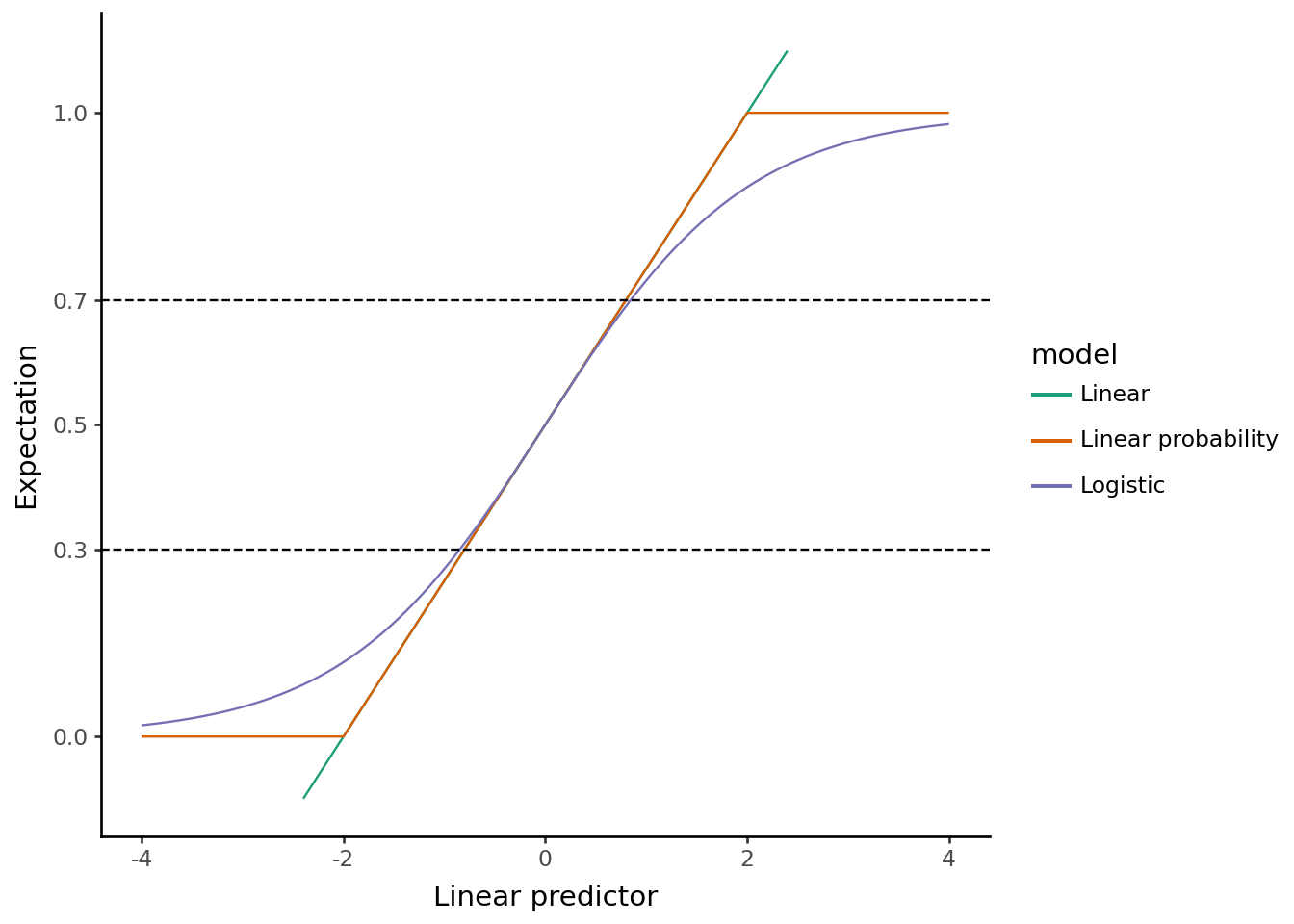
You can even use a gaussian GLM where we don’t transform the linear combination of the features at all.
TipPros and Cons of the linear probability model
The gaussian GLM has the benefit that the coefficients are interpretable on the probability scale directly and it has a (fast to compute) closed form solution.
It also turns out to be unbiased and consistent for the average marginal effect.
However, it can predict probabilities outside of \((0,1)\), so it is only a good approximation for the conditional expectation when the probabilities are between 0.3 and 0.7:
So we have a map between the linear combination of the features (\(X\beta\)) and the probability of the outcome \(p\), but we still need to specify the distribution of the outcomes to get a full generative model.
Given we have outcomes \(y \in \{0,1\}\), and assuming a conditional (on \(x\)) mean \(p\), the maximum entropy distribution is the Bernoulli distribution \[P(y) = p^y (1-p)^{1-y}\]
It’s more succinct, and you also get standard errors (and p-values), however the JAX implementation is more flexible. For example we could easily switch to a probit model by just changing the sigmoid function to the CDF of the standard normal distribution:
def predict_probit(weights, bias, predictors):""" Probabilities of the positive class """return norm.cdf(jnp.dot(predictors, weights) + bias)
While we used standard gradient descent above, with Flax we can use more sophisticated optimisers like Adam which adjust the learning rate for example using momentum.
import flax.linen as nnfrom flax.training import train_stateimport optaxclass LogisticRegression(nn.Module):@nn.compactdef__call__(self, x):# A simple linear layer with 1 output (the logit)return nn.Dense(features=1, use_bias=True)(x)def loss_fn(params, apply_fn, X, y): logits = apply_fn({'params': params}, X).squeeze()return optax.sigmoid_binary_cross_entropy(logits, y).mean()@jax.jitdef train_step_adam(state, X, y): loss_val, grads = jax.value_and_grad(loss_fn)(state.params, state.apply_fn, X, y) updates, new_opt_state = state.tx.update(grads, state.opt_state, state.params) new_params = optax.apply_updates(state.params, updates)return state.replace(params=new_params, opt_state=new_opt_state), loss_valdef train_model(X, y, key): model = LogisticRegression() variables = model.init(key, jnp.ones((1, 2))) tx_adam = optax.adam(learning_rate=0.1) state_adam = train_state.TrainState.create( apply_fn=model.apply, params=variables['params'], tx=tx_adam )for i inrange(101): state_adam, loss = train_step_adam(state_adam, X, y)if i %10==0:print(f"Epoch {i}: Loss = {loss:.4f}")print("Learned Weights: ")print(state_adam.params)train_model(X, y, key)print(f"\nTrue Weights: {true_w}")print(f"True Bias: {true_b}")
Epoch 0: Loss = 1.2306
Epoch 10: Loss = 0.7032
Epoch 20: Loss = 0.5401
Epoch 30: Loss = 0.4987
Epoch 40: Loss = 0.4956
Epoch 50: Loss = 0.4960
Epoch 60: Loss = 0.4958
Epoch 70: Loss = 0.4955
Epoch 80: Loss = 0.4951
Epoch 90: Loss = 0.4950
Epoch 100: Loss = 0.4950
Learned Weights:
{'Dense_0': {'bias': Array([0.30004427], dtype=float32), 'kernel': Array([[ 1.5121937],
[-0.8052652]], dtype=float32)}}
True Weights: [ 1.5 -0.8]
True Bias: 0.3
We can also use LBFG-S, which is a second order optimiser (it uses the Hessian - the matrix of second derivatives). So while each update is more expensive, it doesn’t require as many iterations:
@jax.jitdef train_step_lbfgs(state, X, y): loss_val, grads = jax.value_and_grad(loss_fn)(state.params, state.apply_fn, X, y)# L-BFGS needs value and grad passed to update updates, new_opt_state = state.tx.update( grads, state.opt_state, state.params, value=loss_val, grad=grads, value_fn=lambda p: loss_fn(p, state.apply_fn, X, y) ) new_params = optax.apply_updates(state.params, updates)return state.replace(params=new_params, opt_state=new_opt_state), loss_valdef train_model_lbfgs(X, y, key): model = LogisticRegression() variables = model.init(key, jnp.ones((1, 2))) tx_lbfgs = optax.lbfgs(memory_size=10) state_lbfgs = train_state.TrainState.create( apply_fn=model.apply, params=variables['params'], tx=tx_lbfgs )for i inrange(6): state_lbfgs, loss = train_step_lbfgs(state_lbfgs, X, y)print(f"Epoch {i}: Loss = {loss:.4f}") print("Learnt weights:")print(state_lbfgs.params)train_model_lbfgs(X, y, key)print(f"\nTrue Weights: {true_w}")print(f"True Bias: {true_b}")
Epoch 0: Loss = 1.2306
Epoch 1: Loss = 0.9719
Epoch 2: Loss = 0.5134
Epoch 3: Loss = 0.5010
Epoch 4: Loss = 0.4954
Epoch 5: Loss = 0.4950
Learnt weights:
{'Dense_0': {'bias': Array([0.30116275], dtype=float32), 'kernel': Array([[ 1.5125961],
[-0.8026858]], dtype=float32)}}
True Weights: [ 1.5 -0.8]
True Bias: 0.3
The real power here comes from the flexibility to train almost arbitrary models. A logistic regression is just a single layer neural network, but we can easily add more layers:
class LogisticRegressionNN(nn.Module):@nn.compactdef__call__(self, x):# A simple neural network with 1 hidden layer and 1 output (the logit) x = nn.Dense(features=10, use_bias=True)(x) x = nn.relu(x)return nn.Dense(features=1, use_bias=True)(x)def train_model_nn(X, y, key): model = LogisticRegressionNN() variables = model.init(key, jnp.ones((1, 2))) tx_adam = optax.adam(learning_rate=0.1) state_adam = train_state.TrainState.create( apply_fn=model.apply, params=variables['params'], tx=tx_adam )for i inrange(101): state_adam, loss = train_step_adam(state_adam, X, y)if i %10==0:print(f"Epoch {i}: Loss = {loss:.4f}")train_model_nn(X, y, key)
Epoch 0: Loss = 0.6905
Epoch 10: Loss = 0.5051
Epoch 20: Loss = 0.4985
Epoch 30: Loss = 0.4972
Epoch 40: Loss = 0.4964
Epoch 50: Loss = 0.4956
Epoch 60: Loss = 0.4952
Epoch 70: Loss = 0.4951
Epoch 80: Loss = 0.4950
Epoch 90: Loss = 0.4950
Epoch 100: Loss = 0.4950
While in this case we generated data from the logistic model so we don’t improve much on the loss. For more complicated data generating processes this general model training procedure is quite powerful.